終於把概念跟方法講完了!這個章節我們就來看一下模型的表現有多好,該實驗主要用三個面向去表示模型的能力,除了第一種self-play,讓相同模型測試外,還有不同模型測試的組合,ad-hoc,最後一個則是找人來做意圖的評估,接著去看說,跟人類的判斷比起來,有多相符。
首先要提一下,這邊另外有四個方法去做比較:
左側縱軸部份,可以看到三種等級的環境,橫軸的話,則是三個不同複雜的任務,隨著越右邊步驟越多。每個圖表都有一個是直線圖,一個是折線圖。直線圖的y軸代表走得step,橫軸不同顏色代表五種演算法。右側的折線圖,則是y軸代表完成度,x軸代表steps。
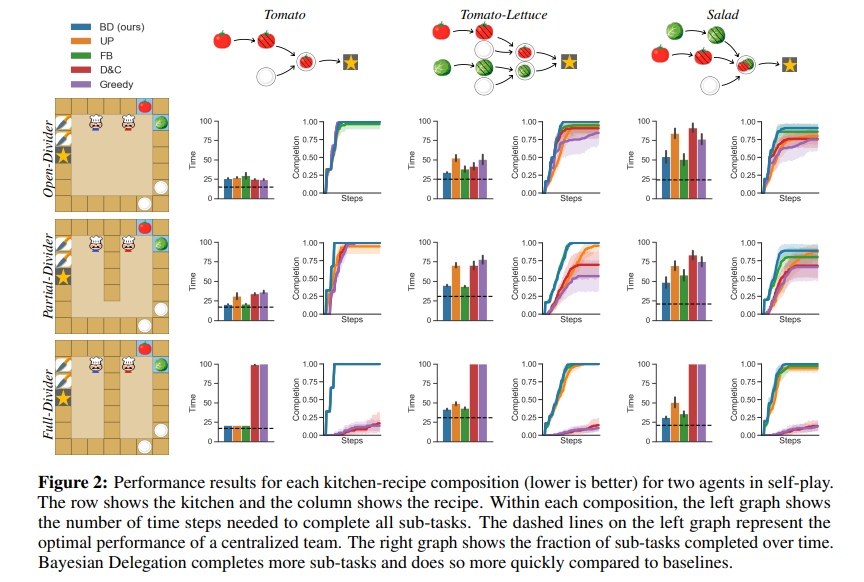
可以觀察到,如果是以3x3為九宮格,最上面一排的任務,是都有完成,顯示環境複雜的的影響。那如果看到最下面這一排,也就是封閉式環境的實驗,則像是D&C與Greedy表現就很差,可能都沒法讀懂彼此間的意圖是什麼。全部的結果,可以看出BD的演算法都是表現最好,或者最快的那一組。
我覺得這篇蠻有趣的一個實驗,就是讓不同的智能體互相合作。體會一下什麼叫做神隊友與豬隊友的組合。可以看到左邊藍色圖塊,只要不是在對角線上的方塊,都是跟其他人合作的結果,數字則是為平均的steps,右邊則是整個合作的數字結果,分別有時間、完成度與Shuffle,這裡Shuffle則是指智能體移動卡住的次數,這邊值越低越好。可以看到BD在三個表線上,都完勝其他的演算法。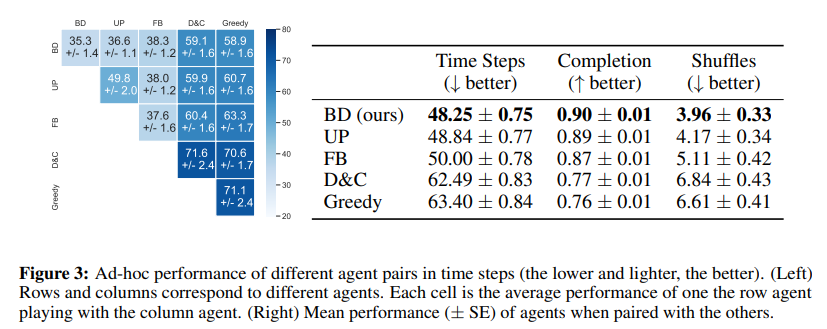
該研究在網路上找了45個志願者,根據畫面去判斷智能體的意圖,那對於每一個動作,有0~1的判斷,0是not likely at all,1為certainly。下面的圖表則是maaping的程度,每個點就是每一次事件的判斷分數,y軸是演算法,x軸是人類的平均判斷,可以看到BD的方法是最符合y=x的直線,也就表示BD的方法最符合人類的判斷,儘管研究上沒有使用到人類的判斷數據集。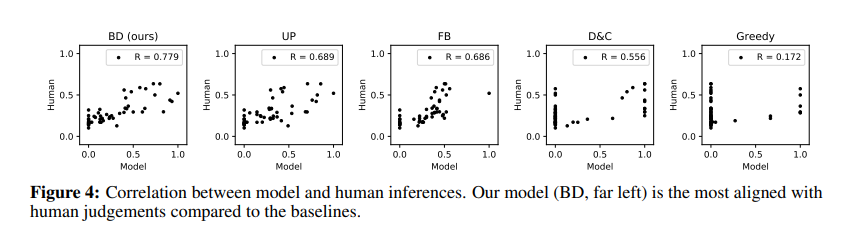
我覺得算是蠻酷的,最後面還找人類來做判斷的比較,其實我覺得那條線沒有真的很穩貼對角線,再來是說附錄的連續性控制,那張圖片有點怪怪的,三個判斷的bar都是在同一個位置,不知道是不是圖片給錯,但覺得以完整性來講,整個研究還算不錯,所以policy那塊要參考附錄,但整體能用 Bayesian Delegation 能作到這種程度,我覺得也蠻酷的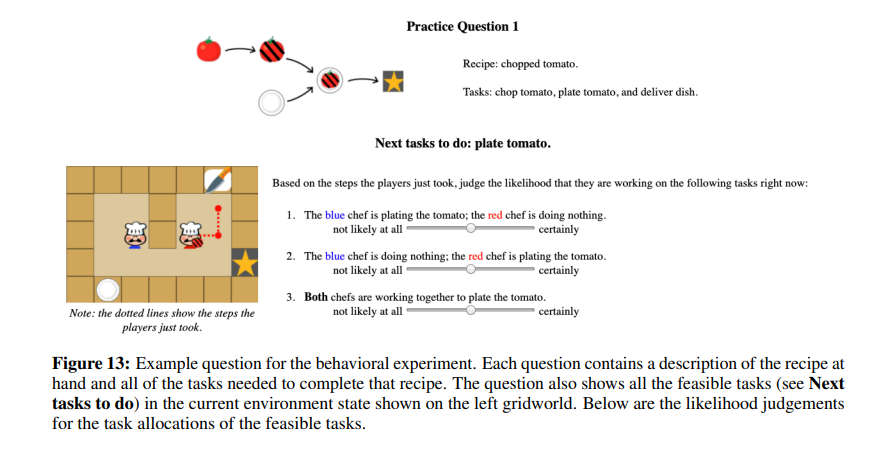
Too many cooks: Bayesian inference for coordinating
multi-agent collaboration


 iThome鐵人賽
iThome鐵人賽